将以前看的Introduction to Programming in Python时做的笔记,特地整理了一下放在博客上。书籍是开源的,内容可以到这个http://introcs.cs.princeton.edu/python/home/网站获取。结构如下:
内置数据类型
整数类型
int数据类型用于表示整数或自然数。
python语言中,int的取值范围可以为任意大,仅受限于计算机系统的可用内存量。
运算
- 加
+ - 减
- - 乘
* - 整除
// - 取余
% - 乘幂
** - 一元运算符
+/-。表示整型数值的正负号。
注意:
**乘幂运算符是右结合。 例如,2**2**3的结果是256。python3中,浮点数除法运算符
/作用于两个整数时,结果为浮点数,这与浮点数除法行为一致。例如,17/2的求值结果是8.5。与python2不一致。
-47//5的求值结果是-10。因为运算符//是向下取整,即向负的无穷大取整。但是,-47%5的求值结果是3,原因是对于表达式a%b,计算结果的符号与b一致。
浮点数
float数据类型用于表示浮点数值。
浮点数字字面量可使用一系列数字加小数点来指定。
运算
- 加
+ - 减
- - 乘
* - 除
/ - 乘幂
**
布尔值
bool数据类型用于表示逻辑值:True / False.
- 逻辑与:
and - 逻辑或:
or - 逻辑非:
not
字符串
str数据类型用于表示文本处理的字符串。
str字面量可使用包括在单引号之间的字符系列指定。
- 运算符
+可以用于拼接两个字符串,然后返回一个新的str对象。 - 内置函数
str()可把数值转换为字符串。
比较运算符
- 等于:
== - 不等于:
!= - 小于:
< - 小于或等于:
<= - 大于:
> - 大于或等于:
>=
类型转换
显式类型转换
显示类型转换使用转换函数进行类型转换
str(x)- 将x转换为字符串数据类型int(x)- 将字符串x转换为整数数据类型,或者将浮点数x转换为整数数据类型float(x)- 将字符串或整数x转换为浮点数据类型round(x)- 四舍五入取整
隐式类型转换
- 整数到浮点数:python会自动将整数转换为浮点数
选择结构和循环结构
选择结构
if语句
语法:
if <boolean expression>:
<statement>
<statement>
...
上述
if语句解释为:如果“布尔表达式”的求值结果是True,则执行缩进部分的语句块。语句块下出现第一个非缩进 的行表示语句块的结束。
else语句
if语句中可以加入else语句。
语法:
if <boolean expression>:
<block of statements>
else:
<block of statements>
循环结构
while语句
语法:
while <boolean expression>:
<statement>
<statement>
while语句中缩进的语句块称为循环体,布尔表达式称为循环测试条件。
for语句
for语句有多种语法格式。其一为:
for <variable> in range(<start>,<stop>):
<block of statements>
内置函数
range()的参数<start>和<stop>必须是整数。第一次循环时,<variable>的值为<start>,每次循环后<variable>的值+1,直至最后一次循环时,<variable>的值为<stop>-1。
对于range()只带一个参数,则该参数为<stop>的值,<start>的默认值为0。
循环和中断
break语句
可表达为:执行一系列语句,如果满足循环终止条件,则退出循环。
举例
while Ture:
statement
statement
if <boolean expression>:
break;
数组
数组是一种数据结构。主要功能是存储和处理大量数据。
一维数组
创建数组
最简单的方法就是在方括号中放置逗号分隔的字面量。
suits = ['Clubs', 'Diamonds', 'Hearts', 'Spades']
x = [0.30, 0.60, 0.10]
引用数组元素:数组名后跟方括号,方括号中指定索引,即
x[i]引用数组的第i个元素。x引用整个数组。
- 从0开始的索引
- 数组长度:使用python的内置函数
len()返回数组所包含元素的个数 - 可以使用
+=扩展数组的长度。 - 数组的元素是可以更改的。
- 内置函数:除
len()之外,还包括sum()/max()/min()等
数组别名
如下语句:
x = [0.30, 0.60, 0.10]
y = x
x[1] = 0.99
y是x的别名(类似于C中的引用)。y[1]的结果同样是0.99。
数组复制
python中复制数组的一个方法是遍历数组:
y = []
for v in x:
y += [v]
for v in x:是直接遍历数组,和for v in range(len{a}):的效果是一致的。
数组切片
使用数组切片操作可以复制一个数组中任意连续系列的元素到另一个数组。
a[i:j]
新数组所包含的元素为:a[i],...,a[j-1]
y = x[:]
x[:]中,i默认为0,j默认为len(a)
创建数组与初始化
一般代码可以这样实现:
a = []
for i in range(n):
a += [0.0]
甚至可以直接使用:
a = [0.0]*n
二维数组
创建数组
最简单的方法是在方括号中包括以逗号分隔的一维数组。
a = [[18, 19, 20], [21, 22, 23]]
初始化
a = []
for i in range(m):
row = [0.0]*n
a += [row]
创建了一个m*n的浮点型数组。
函数
函数定义

- 第一行为函数签名(signature),用于指定函数名称(function name)和每个形式参数变量名称。函数签名包括关键字
def、函数名、一个或多个形式参数变量名、英文冒号。 - 紧跟函数签名后的缩进代码定义函数体(function body)。
- 函数体中还可以包含一条
return语句。 - 函数体还可以定义局部变量(local variable)
控制流程
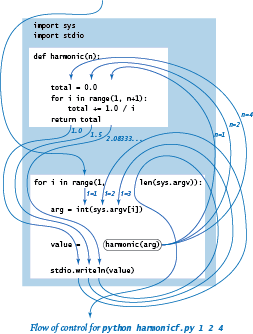
- 首先,处理
import语句。 - 然后,Python处理函数定义,但不会执行函数,仅当调用函数时Python才会执行函数。
- 执行全局代码。
注意:函数定义的位置必须位于调用该函数的全局代码之前。
变量的作用范围
- 函数的局部变量和形参变量的作用范围仅限于函数本身。
- 全局代码中定义的变量(全局变量)的作用范围局限于包含该变量的整个
.py文件。 - 全局代码不能引用一个函数的局部变量或形参变量。
- 一个函数也不能引用在另一个函数中定义的局部变量或形参变量。
- 如果在一个函数中定义的局部变量(或形参变量)与全局变量重名,则局部变量优先。
软件设计的指导原则是:定义变量的作用范围越小越好。所以,强烈建议不要在函数中引用全局变量:应该使用函数形参变量实现与其函数的通信,而函数则应该使用
return语句实现与其调用者的所有通信。
默认参数
- 有些API函数如
math.log(x)和math.log(x, b),如果只传入一个函数,则b默认为自然对数e。 - 在自定义函数中,通过在函数签名的参数变量后使用等号和默认值,指定该形式参数变量为带默认值的可选参数。
def harmonic(n, r=1)
类型检查
Python语言中,不用指定形式参数变量的类型,也不用指定返回值的类型。
只要Python能够完成函数中的所有运算操作,Python就会执行完函数并返回结果。
如果由于给定对象的类型不匹配,Python无法完成一个运算操作,Python将抛出一个运行错误并指出错误类型。
这称为多态性(polymorphism)
传递参数和返回值
通过对象引用实现调用
Python使用调用传递对应的实际参数来初始化形式参数变量。我们称之为“通过对象引用实现调用(call by object reference)”。(更常见的说话是值调用)
不可变性和别名
一个数据类型是不可变的(immutable),是指该数据类型对象的值是不可变的。
数据类型(int/float/str/bool)都是不可变的。对于不可变的数据类型,有些操作看上去修改了对象的值,但实际上创建了一个新的对象。
例如:
i = 99
j =i
j += 1
首先,语句
i = 99创建了一个整数对象99,并把指向该对象的引用赋值给了变量i。然后执行语句j = i,把i(赋值引用)赋值给j,所以变量i和j都引用同一个对象。如果两个变量指向同一个对象,则互称别名。最后,执行j += 1,其结果是j引用一个值为100的对象,但语句并没有将已存在的值为99的整型对象的值改变为100。实际上,因为int对象为不可变对象,所以没有语句可以改变一个既存整型对象的值。事实上,该语句创建了一个新的整型对象1,加上整数99并创建另一个新的整型对象100,并把指向该整数的对象引用赋值给变量j。但是,i依旧指向原来的99。
所以传递实际参数给一个函数,实参和形参是互为别名。
举例:
def inc(j)
j += 1
i = 99
inc(i)
此时,
i和j互为别名。函数inc()的语句j += 1不会改变整数99,而是创建一个新的整数100,并把其对象引用赋值给变量j。但是,当函数inc()调用结束返回到调用者后,其形式参数变量j超出了作用范围,而变量i依旧指向整数99。
数组作为参数
数组是可变(mutable)的数据类型,我们可以改变数组元素的值。
所以,当传递一个数组作为函数的实际参数时,可以直接操作该数组(而不是该数组的副本)
举例
def exchange(a, i, j)
temp = a[i]
a[i] = a[j]
a[j] = temp
x = [.30, .60, .10]
exchange(x, 0, 2) >运算过后,`x = [0.10, 0.60, 0.30]`
模块和客户端
调用其它程序中的函数的步骤
- 模块(module):包含可被其他程序调用的函数
- 客户端(client):是调用其它模块中的函数的程序
在客户端导入模块
在客户端中,编写函数:
import module
目的是通知Python,客户端代码可能会调用定义在module.py中的一个或多个函数。
在大多数Python代码中,
import语句位于程序的最开始的位置,导入标准模块的所有import语句则位于用户自定义模块的前面。
在客户端中限定函数调用的模块
要调用module.py中的函数,可以使用如下方式:
module.函数名
在模块中编写测试客户端
程序员坚持多年的最佳编程实践,就是编写代码以测试模块中各函数的功能并且将测试代码包括在模块中。
Python语言长久以来的传统是吧测试代码放置在名为main()的函数中。
如下:
def main():
测试代码
if __name__ == '__main__':main()
在模块中消除全局代码
import语句会执行导入模块中的所有全局代码,所以在模块中不能遗留全局代码(这些测试代码常常向标准输出写入内容)。
替代方法是,将测试代码放置在main()函数中,并制定当且仅从命令行执行程序时Python才会调用测试函数main(),使用如下:
if __name__ == '__main__':main()
上述代码只是Python当
.py文件从命令行直接执行时(而不是通过import语句)调用main()。
使得模块可被客户端调用
当模块不是Python内置或标准模块时,Python首先在于程序client.py相同的目录中查找模块文件。所以,最简单的方法是把客户端程序文件和模块文件放在相同目录下。
模块化程序设计
实现(Implementation)
通常使用术语’Implementation’来描述实现重用的若干函数的代码。一个Python模块就是一个实现。
模块设计的指导性原则是:为客户端提供需要的函数,不要包含其他多余的内容
客户端(Client)
通常使用通用术语’Client’表示使用一个实现的程序。
应用程序编程接口(API)
API允许任何客户端直接使用模块,而无须检测模块中定义的代码。
私有函数(Private function)
有时候需要在模块中定义辅助函数,辅助函数不能被客户端直接调用,称为私有函数。
根据惯例,Python程序员使用下划线开始的函数名作为私有函数。
def _functionname(x):
API一般不包括私有函数。
以下划线开始的函数名指示客户端不要直接调用这些函数,但Python并没有强制不允许调用私有函数的机制。
库(Library)
库是若干相关模块的集合
文档(Documentation)
通过Python交互式的内置函数help(),可查看标准库、扩展库模块的API。具体实施如下:
>>> import modulename
>>> help(modulename)
对象
在Python中,所有的数据都表示为对象及对象之间的关系。Python对象是特定数据类型的值在内存中的表现方式。每个对象由其标志(identity)、类型(type)和值(value)三者标识。
- 标志用于唯一标识一个对象,你可将标志看作对象在计算机内存(或内存地址)中的位置。
- 类型用于限定对象的行为–对象所表示的取值范围以及允许执行的操作集合
- 值用于表示对象数据类型的值
对象引用
对象引用是指对象标志的具体表示,即存储对象的内存地址
变量
对象引用的名称
递归
递归的含义
函数调用自身
编写递归函数必须小心
不能缺少基本情况
否则,递归函数将重复调用自身,永远不会终止。
最终,Python会抛出RuntimeError,并报告错误信息maximum recursion depth exceeded。
不能保证收敛
过量的内存需求
调用自己的次数太多,Python无法保证保存递推调用所需的内存足够,从而导致maximum depth exceeded错误。
避免过量的重复计算
面向对象的程序设计
数据类型
Python语言中的数据类型包括两类:
- 内置数据类型(int / bool / float /str)
- 用户自定义数据类型
一个数据类型是一系列值的集合以及定义在这些值上的一系列操作的集合
方法
调用方法的语法是:
变量名.方法名
方法是特定对象(即与对象的数据类型)相关联的函数。必须显式地关联一个指定的对象。
举例:
x = 3 ** 100
bits = x.bit_length()
stdio.writeln(bits)
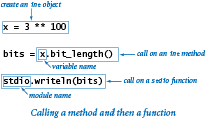
上述代码中,
x.bit_length()就是方法调用,stdio.writeln(bits)就是函数调用。
字符串处理
str的API运算操作可分为三个类别:
- 内置运算符:
s + ts +=ts[i]s[i:j]s[i:j:k]s < ts != ts > t- and so on
- 内置函数:
len()- and so on
- 方法:
s.count()s.find()s.upper()s.lower()s.strip- an so on
实际上,上述三种运算操作的实现方法是一致的。Python自动将内置运算符和内置函数映射到特殊方法,特殊方法约定使用名称前后带双下划线的命名规则。
比如:
s + t等价于方法调用s.__add__(t);len(s)等价于函数调用s.__len__()。
用户自定义数据类型
API
主要是指定构造函数,方法和内置函数。
文件命名规则
一般将用户自定义数据类型的代码保存在一个独立的.py文件中,文件名与数据类型相同但不大写。在客户端我们需要通过以下的语句引入自定义的数据结构:
from charge import Charge
charge是文件名charge.py除去后缀的部分,Charge是自定义数据类型名。
用户自定义数据类型和内置数据类型的不同之处
内置数据类型在Python中拥有特殊地位:
- 可直接使用内置数据类型而无须通过
import引入 - Python为创建内置数据类型的对象提供了特殊的语法
- 按惯例,内置数据类型以小写字母开始,用户自定义数据类型则以大写字母开始
- Python为内置的算术数据类型提供自动类型转换
- Python为内置数据类型的转换提供了内置函数
创建数据类型
3个基本步骤:
设计其API:至关重要
这是我们构建一个新的数据类型的蓝图
实现一个Python类以满足API规范
- 编写构造函数
实现一个特殊方法:
__init__()
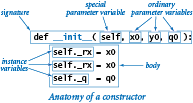
按惯例,第一个参数变量的名称是
self,作为Python默认对象创建过程,当__init__()被调用时,self参数变量的值指向新建对象。
实例变量(Instance variable)属于类的特定实例,即一个特定对象。
遵循规范,只能在构造函数中定义和初始化一个新建对象的实例变量,实例变量名以下划线开始。
对象创建的详细过程
- Python创建对象,并调用
__init__()构造函数,初始化构造函数的self参数变量为新建对象的引用。 - 构造函数定义和初始化
self引用的新建对象的实例变量 - 当构造函数执行完毕,Python自动把执行新建对象的
self引用返回给客户端 - 客户端把引用赋值给变量
- 编写方法处理实例变量以实现功能
实现一个方法
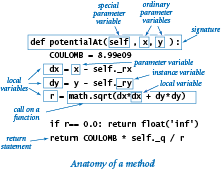
方法可以访问实例变量。
方法的第一个参数变量名是self,当客户端调用一个方法时,Python自动设置self参数变量为指向当前操作的对象的引用,即调用方法的对象。
方法中的变量
self对象的实例变量- 方法的参数变量
- 局部变量
每个局部变量或参数变量对应一个唯一的值,但每个实例变量则可能对应多个值(数据类型的每个对象、实例对应一个值)。
另外,参数变量和局部变量的作用域是方法中,实例变量是类中。
实现一个内置函数
我们实现一个函数名的前后均带双下划线的特殊方法,其第一个参数变量为self。
比如:内置函数str(c),按照Python规范,str(c)函数调用会自动转换为一个标准方法调用c.__str__()
这是一种多态性。也具有私有性。
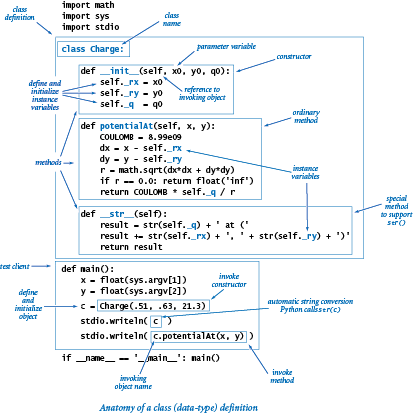
设计数据类型
设计API
通常,构建软件最重要的和最具挑战性的步骤就是设计API。
- 符合API标准,通过API把客户端和实现分隔开来
- 数据类型API包含若干方法和这些方法所提供功能的简洁描述,准确描述所有可能参数行为,包括副作用,然后编写软件检查其实现是否满足规范要求
- 避免宽接口(Wide interface),不要有数量众多的方法接口。很容易在一个既存的API中增加方法,然而移除方法但又要保证不破坏既存客户端则十分困难。
- 从客户端代码开始
- 避免对表示方式的依赖
- 为客户端仅提供所需的方法,仅此而已
封装
将客户端和实现分离从而隐藏信息的过程称为封装。其主要目的是:
- 实现模块化设计
- 提高调试效率
- 是代码更加简洁
- 修改API
一旦众多数量的客户端在使用一个模块,请千万不要随意改变其API
- 改变实现
封装的设计理念在于:我们可以使用一个程序代替另一个程序,而无须修改客户端代码
- 私有性
Python编程社区提出一个规范:如果一个实例变量、方法或函数的名称以下划线开始,那么客户端应该把该实例变量、方法和函数作为私有变量。
通过这种命名规范,客户端被告知不应该直接访问名称以下划线开始的实例变量、方法和函数。
不可变性
如果对象的数据类型值一旦创建就不可更改,则称对象为不可变对象。
元组(Tuple)
Python内置数据类型tuple表示一个不可变的对象序列。元组类似于内置数据类型list(也称作数组),不同之处在于一旦创建了一个元组,就不能修改其元素。
在需要修改序列元素的情况下,则必须使用数组。
Python还支持一种强大的元组赋值功能,称为元组组包(tuple packing)和元组解包(tuple unpacking),允许用户把右侧的一个表达式元组赋值给左侧的变量元组。
注意:必须保证左侧的变量个数和右侧的表达式个数一致。
多态性
可带不同类型参数的方法或函数称为多态性。
运算符重载
在数据类型中提供运算符的自定义能力是一种多态性,称为运算符重载。
Python用于支持重载的机制是将每个运算符和内置函数与一个特殊方法关联起来。
例如:每当Python发现Python发现客户端代码中的
x + y,则将该表达式转换为特殊方法调用x.__add__(y)。因而,要在自定义数据类型中重载+运算符,则只需包含特殊方法__add__()的一种实现即可。
算术运算符
x + y: ` add(self, other)`x - y:__sub__(self, other)x * y:__mul__(self, other)x ** y:__pow__(self, other)x / y:__truediv__(self, other)x // y:__floordiv__(self, other)x % y:__mod__(self, other)+x:__pos__(self, other)-x:__neg__(self, other)
等性运算符
用于测试相等与否的运算符==和!=值得特别注意。因为Python中有两种相等的方式:
- 引用相等(标识相等): 当两个引用相等(即引用同一个对象)时,引用相等成立。内置函数
id()返回对象的内存地址。is和is not运算符测试两个变量是否引用同一对象。 - 对象相等(值相等):当两个对象相等(即包含相同数据类型值)时,对象相等成立。我们应该使用运算符
==和!=(定义为特殊方法:__eq__()和__ne__())测试对象的相等性。
如果没有定义
__eq__()方法,则Python使用is运算符代替,即默认==实现为引用相等性。
哈希法
略。
比较运算符
x < y:__lt__(self,other)x <= y:__le__(self,other)x >= y:__ge__(self,other)x > y:__gt__(self,other)
其他运算符
在Python语言中,几乎所有的运算符都可以被重载。
内置函数
可以重载内置函数。
len(x):__len__(self)float(x):__float__(self)int(x):__int__(self)str(x):__str__(self)abs(x):__abs__(self)hash(x):__hash__(self)iter(x):__iter__(self)
函数是对象
在Python语言中,一切(包括函数)皆是对象。
这意味着函数可以作为另一个函数的参数和返回值,这种做法叫做高阶函数。
继承
继承的使用存在争议,因为继承一般会与封装违背。所以,略。